I got my OCM. Hurray!
Now one of the common question people ask me is how to pass this OCM exam.
Firstly I am very grateful to Oracle to introduce this exam. Finally it is the real exam, but not test with set of answers. I clearly see complicatedness for examiners, but it is the real proof of DBA skills, not general memory skills.
Secondly this exam does not prove your exceptional knowledge of Oracle. It is the proof that you are fluent in all basic skills. During the exam everything works according to documentation. Personally I have collection of my favourite Metalink Notes and Advanced instructions that are used at least once a week. You do not need such things on exam.
The environment is ready. You do not need to reconfigure switches for RAC or install additional OS packages. What you are doing is only Oracle Database Administration, no OS specific. If something is really different between different UNIX OS, forget about it. It should not be part of the exam.
When I came to client site I frequently have no access to internet thus have a copy of Oracle Documentation locally. Moreover reading through local copy is actually faster then browsing through internet copy. I used to use local copy and it was really useful during exam.
Another my habit that I find useful is preparing all scripts in text file and then copy it to SQL*Plus or Shell window. If you need to rerun script or slightly alter it for a different skill-set you can reuse your one history. E.g. I store in this file backup/restore scripts.
You have 2 days, 14 hours, including lunch and breaks for 7 skill-sets. None of skill-set takes more then 2 hours. If you do not believe you can do something in less then 2 hours forget about it. Even if it would be on exam you would not be able to do it in time. Focus on things that you would be able to do.
The exam is based on 11.2g database. If something is different between patch sets again forget about it. Asking information specific for patch set is unfair to people who used to basic one, thus this question would not arrive on exam.
When you read through skill-set task at the beginning, read it up to the end. Mark for yourself tasks that would require you some investigation through the documentation. Mark for yourself tasks that you doubt to solve. Estimate time for each task. Start from the short and easy one and if you significantly overflow the time frame you set switch to the next task in your ordered list. If you have time you can came back and fix the issues later.
I recommend 15 minutes before end of skill-set to check the whole environment, there is special button for end state of the skill-set. 15 minutes should be enough to bring it to correct state.
Read tasks carefully, frequently tasks include markers how to avoid hidden rocks of the environment, e.g. check all options of the objects to create. If you would not follow it exactly the problems would make your life significantly harder.
Some tasks are not clear, you can ask your proctor for clarification. But proctor not always can rephrase task without violation of exam rules, if he could not provide explanation what is requested in a task follow “best practice”.
In general be concentrated, careful and have a lot of practice before exam. I passed preparation courses but honestly it was just way to guarantee time and environment for training. You can do preparation yourself if your management and family would grant the opportunity to do it. If you have no such generous option apply for a preparation course, it is really value for money, very useful and informative. Course provide to you experience of working on the same machines that you would use on exam. In my case the machines was really physically the same, just different OS image. BTW try to became used to local keyboards of the country where you are going to pass the exam. English and US keyboards are different and this difference can be that point which consume the vital time on exam.
Good Luck.
Eter
Author Archives: Eter Pani
Oracle Dictionary fragmentation
The purpose of this post is mainly to highlight the performance degradation due to dictionary index fragmentation. It is something that oracle not widely announce but it came from the physical structure of the database.
Oracle databases have the AGE and the age mainly came from the number of DDL operations done on the database. The DDL operations modify the dictionary and introduce fragmentation to the indexes and tables.
I have made the small test case
-- CREATE TABLE
DROP TABLE list_customers
/
CREATE TABLE list_customers
( customer_id NUMBER(6)
, cust_first_name VARCHAR2(20)
, cust_last_name VARCHAR2(20)
, nls_territory VARCHAR2(30)
, cust_email VARCHAR2(30))
PARTITION BY LIST (nls_territory) (
PARTITION asia VALUES ('CHINA', 'THAILAND'),
PARTITION europe VALUES ('GERMANY', 'ITALY', 'SWITZERLAND'),
PARTITION west VALUES ('AMERICA'),
PARTITION east VALUES ('INDIA'))
/
-- ADD partitions
ALTER SESSION SET EVENTS '10046 trace name context forever, level 4'
/
ALTER TABLE list_customers ADD PARTITION south VALUES ('ANTARCTICA')
/
EXIT
-- DROP partition
ALTER SESSION SET EVENTS '10046 trace name context forever, level 4'
/
ALTER TABLE list_customers DROP PARTITION south
/
EXIT
It is oversimplified method without dependancies to the object and object statistics. But it already create two massive traces.
In summary during the INSERT command we insert to tables
OBJ$, DEFERRED_STG$ and TABPART$
During delete operation we remove rows from this tables
As you all know insert-delete tables have high level of fragmentation on the indexed columns
We run the standard report for indexes on 3 mentioned tables and it shows that estimated number of leaf blocks for some of them dramatically smaller then the actual one.
| INDEX | Estimated Size | Actual Size |
| SYS.TABPART$.I_TABPART_OBJ$ | 47 | 279 |
| SYS.OBJ$.I_OBJ3 | 4 | 20 |
| SYS.OBJ$.I_OBJ4 | 422 | 1475 |
| SYS.OBJ$.I_OBJ1 | 422 | 969 |
| SYS.TABPART$.I_TABPART_BOPART$ | 68 | 125 |
| SYS.DEFERRED_STG$.I_DEFERRED_STG1 | 30 | 53 |
| SYS.OBJ$.I_OBJ5 | 1269 | 1728 |
| SYS.OBJ$.I_OBJ2 | 1269 | 1726 |
In case you would try to rebuild this indexes in usual way, you would get the oracle error
ORA-00701: object necessary for warmstarting database cannot be altered
that actually block all attempts to fix the fragmentation.
Index fragmentation primarelly affect index FULL and RANGE scans operation but not UNIQUE index scan. UNIQUE scan would be affected only when INDEX would grow for additional level.
The number in a table does not show something dramatic but it looks like we already have mensurable performance impact on common database operations, like name resolution.
In long term I think every database with high number of structure modifications has to go through process of APPLICATION DATA migration regularly once in 5-15 years.
NOLOGGING in numbers
Hi All
I have made small investigation about redo generation. From early days of my career I was remember that nologging operation is very performance effective but never try to quantify this very.
Every application can theoretically be split into 4 groups of tables (I use my personal names but hopefully it has sense):
1) Regular tables – contain valuable information need to be stored for legal and functional purposes. Stored as normal tables.
2) Staging tables – contain process lifetime specific information, easily re-creatable. Used for transferring information between sessions and report generation. Stored as regular tables or materialized views.
3) Session Temporary tables– contain process lifetime specific information, easily re-creatable. Used for reporting stored as GLOBAL TEMPORARY tables ON COMMIT PRESERVE.
4) Transaction Temporary tables– contain process lifetime specific information, easily re-creatable. Used for processing optimisation stored as GLOBAL TEMPORARY tables ON COMMIT DELETE.
By default all 4 groups generate REDO logs records that can be significant amount of resources. The redo information is valuable if we:
1) Support StandBy database
2) Information inside tables is valuable and have to be safe in case of database crush.
To make the standby or backup completely usable after a nologging statement is run, a mechanism other than database recovery must be used to get or create current copies of the affected blocks. You have to drop and recreate the object with the invalidated blocks or truncate it, using the program that maintains the object. Thus extra step to manage switchover/failover to standby database process have to be introduced.
Again based on my understanding the only business requirements for logging is to keep data from “Regular tables”. The safety of the data from other groups is not such important.
The only DML operation that can be optimised in terms of REDO log generation is INSERT with APPEND hint. (MERGE is actually presentation layer above INSERT thus can be treated together) . Hint APPEND if it works have one negative issue. The data in new table is not actually available until end of transaction.Due to the following error.
ORA-12838: cannot read/modify an object after modifying it in parallel
It linked to the fact that oracle could not make consistent model of block if there is no UNDO information. This actually makes using this hint on Global Temporary tables with ON COMMIT DELETE rows unreasonable. You can insert data but never be able to use it until it would be deleted.
Another fact that I have to highlight UPDATE and DELETE always generate REDO information. Thus if the table intensively update the gains would be minimal. Avoiding this operation on a temporary tables is another skills that developers have to be used to for optimal performance of your application.
There are 5 parameters that actually affect SEGMENT logging: Database LOGGING, Database FORCE LOGGING, Tablespace LOGGING, Tablespace FORCE LOGGING (Can be switched on tablespaces with “Regular tables” and switched off on tablespaces with “Staging tables” , Table LOGGIN. Global Temporary tables actually always in NOLOGGING mode thus we can assume for table groups “Session Temporary tables” and “Transaction Temporary tables” always have all parameters equal to NO. Production databases should always be in protected mode thus the value DATABASE LOGGING should always be in YES, it takes value NO outside of investigation.
To test I have created the table TEST.BIGTABLE (column1 NUMBER) with 39999960 rows and few tables to generate INSERT as SELECT statement from BIGTABLE dataset. The results are below.
Regular table
| TABLE LOGGING | * | * | N | Y | N | Y | Y |
| TABLESPACE LOGGING | * | * | Y | N | N | Y | Y |
| TABLESPACE FORCE LOGGING | * | Y | N | N | N | N | N |
| DATABASE LOGGING | Y | Y | Y | Y | Y | Y | Y |
| DATABASE FORCE LOGGING | Y | N | N | N | N | N | N |
| Amount of redo for INSERT APPEND | 501000K | 501000K | 457K | 501000K | 456K | 501000K | 501000K |
| Amount of redo for Standard INSERT AS SELECT | 501000K | 501000K | 501000K | 501000K | 501000K | 501000K | 501000K |
Amount of redo for temporary tables
| Standard INSERT AS SELECT | INSERT APPEND value | |
| Transaction Temp Table | 110K | 0.3K |
| Session Temp Table | 110K | 0.3K |
Hope all above have sense and can be used for good
P.S. The “redo size” values has been got from AUTOTRACE statistics.
Column Encryption tricks
This story starts when someone ask me to Look on Transparent Data Encryption issue. We discover that we could not do Partition Exchange due to the difference in encryption keys on the involved table columns. It have clear common sense to bring them in sync thus we happy trying to implement Oracle Recommendation (Unable To exchange A Partition With A Table If It Has An Encrypted Column [ID 958728.1]) using the following scripts.
ALTER TABLE TESTTBL MODIFY (COL1 decrypt); ALTER TABLE TESTTBL MODIFY (COL1 encrypt using '3DES168' identified by "MyKey2013"); ALTER TABLE TESTTBL MODIFY (COL2 decrypt); ALTER TABLE TESTTBL MODIFY (COL2 encrypt using '3DES168' identified by "MyKey2013");
But it does not change the situation. Why keys are different and how to check it. Officially oracle does not provide any information about encrypting keys but… the following query returns it to me.
SELECT u.name OWNER, o.name TABLE_NAME, c.name COLUMN_NAME,
case e.ENCALG when 1 then '3 Key Triple DES 168 bits key'
when 2 then 'AES 128 bits key'
when 3 then 'AES 192 bits key'
when 4 then 'AES 256 bits key'
else 'Internal Err'
end KEY_TYPE,
decode(bitand(c.property, 536870912), 0, 'YES', 'NO'),
case e.INTALG when 1 then 'SHA-1'
when 2 then 'NOMAC'
else 'Internal Err'
end KEY_ALG,
e.COLKLC as KEY_VAL
from sys.user$ u, sys.obj$ o, sys.col$ c, sys.enc$ e
where e.obj#=o.obj# and o.owner#=u.user# and bitand(flags, 128)=0 and
e.obj#=c.obj# and bitand(c.property, 67108864) = 67108864
ORDER BY 1,2,3;
Actually it is not THE KEYS but the keys encrypted by master key that I do not know, but for our purpose when we just compare the keys it provide required information.
| EPANI | TESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
|---|---|---|---|---|---|
| 4177414141414141414141414141414141414141414141462F5955334D6532392B54453450566747626F4F7570635A51454162786335394A4A524D4E30576335366370344F6D5A364A37515365544F7A6C4B4C534C77633D | |||||
| EPANI | TESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141462F5955334D6532392B54453450566747626F4F7570635A51454162786335394A4A524D4E30576335366370344F6D5A364A37515365544F7A6C4B4C534C77633D | |||||
| EPANI | ARCHTESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
| EPANI | ARCHTESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
Now we see that encryption keys are still different. Lets do it one more time running one command at the time.
ALTER TABLE TESTTBL MODIFY (COL1 decrypt);
| EPANI | TESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
|---|---|---|---|---|---|
| 4177414141414141414141414141414141414141414141462F5955334D6532392B54453450566747626F4F7570635A51454162786335394A4A524D4E30576335366370344F6D5A364A37515365544F7A6C4B4C534C77633D | |||||
| EPANI | ARCHTESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
| EPANI | ARCHTESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
We got 3 rows. The column was decrypted successfully.
Lets run the second command from our script.
ALTER TABLE TESTTBL MODIFY (COL1 encrypt using '3DES168' identified by "MyKey2013");
The command has run successfully but what we have in a key table?
| EPANI | TESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
|---|---|---|---|---|---|
| 4177414141414141414141414141414141414141414141462F5955334D6532392B54453450566747626F4F7570635A51454162786335394A4A524D4E30576335366370344F6D5A364A37515365544F7A6C4B4C534C77633D | |||||
| EPANI | TESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141462F5955334D6532392B54453450566747626F4F7570635A51454162786335394A4A524D4E30576335366370344F6D5A364A37515365544F7A6C4B4C534C77633D | |||||
| EPANI | ARCHTESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
| EPANI | ARCHTESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
We got 4 rows but the encryption key has not changed. At this point we can put our attention that for all columns in the same table the encryption key is the same, even for those which was encrypted without “identified by” clause.
Now we try to decrypt both columns at once and then encrypt both columns back.
ALTER TABLE TESTTBL MODIFY (COL1 decrypt); ALTER TABLE TESTTBL MODIFY (COL2 decrypt); ALTER TABLE TESTTBL MODIFY (COL1 encrypt using '3DES168' identified by "MyKey2013"); ALTER TABLE TESTTBL MODIFY (COL2 encrypt using '3DES168' identified by "MyKey2013");
And check the status of encrypt keys in a storage.
| EPANI | TESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
|---|---|---|---|---|---|
| 4177414141414141414141414141414141414141414142622B726E53615843627A437379797646783333745031517833496542486D514D55765138724A4E4967525A7248534B706C735148756D454C745243597A6C6B6B3D | |||||
| EPANI | TESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414142622B726E53615843627A437379797646783333745031517833496542486D514D55765138724A4E4967525A7248534B706C735148756D454C745243597A6C6B6B3D | |||||
| EPANI | ARCHTESTTBL | COL1 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
| EPANI | ARCHTESTTBL | COL2 | 3 Key Triple DES 168 bits key | YES | SHA-1 |
| 4177414141414141414141414141414141414141414141536576676A5A79514B544B50592F3257762F3359726A6D6A63525747634A6F4B53754645665A7139376677336C394E306D3071706C6667306B6564586233524D3D | |||||
As you see in resultset, the columns reencrypted using new key.
Explanation.Oracle use single key to encrypt all columns in a single table and until you fully decrypt all columns in a table the newly encrypted columns would still use the old keys. I fully understand logic behind it, but it would have more sense get raise an error when you try to encrypt column using specific derivation key but could not do it, rather silently encrypt column using different key.
Dynamic temporary tablespace switching bug/feature.
Up to last day I was absolutely sure that in Oracle terms USER and SCHEMA actually synonyms. The schema does not have attributes and exists just like container for user objects. I was doing some R&D about allocating different TEMPORARY Tablespaces to different users in a system when discover that the same user use different tablespaces in different sessions, without any configuration changes.
I have two temporary tablespaces TEMP and TESTTEMP. Tablespace TEMP is default and associated to all users except TEST.
SELECT USERNAME,TEMPORARY_TABLESPACE FROM DBA_USERS WHERE USERNAME='TEST';
| USERNAME | TEMPORARY_TABLESPACE |
|---|---|
| TEST | TESTTEMP |
We have table TESTTABLE with 100000 rows. And I create spacial sql with massive sort operation.
SELECT * FROM TEST.TESTTABLE a FULL OUTER JOIN TEST.TESTTABLE b on a.COL1=b.COL2 FULL OUTER JOIN TEST.TESTTABLE c on b.COL1=c.COL1 ORDER BY 1,2,3,4,5,6,7,8,9;
By default the query use expected TESTTEMP tablespaces
SELECT S.sid, S.username, SUM (T.blocks) * 8192 / 1024 / 1024 mb_used, T.tablespace FROM gv$sort_usage T, gv$session S WHERE T.session_addr = S.saddr AND t.inst_id=S.inst_id GROUP BY S.sid, S.username, T.tablespace ORDER BY sid;
| SID | USERNAME | MB_USED | TABLESPACE | 23 | TEST | 408 | TESTTEMP |
|---|
But when I change the CURRENT_SCHEMA in a session (ALTER SESSION SET CURRENT_SCHEMA=SYSTEM;) I got different results
| SID | USERNAME | MB_USED | TABLESPACE | 23 | TEST | 487 | TEMP |
|---|
The same query using the same objects from the same session without changing user configuration use different Temporary Tablespaces. I believe this feature can be very helpful for fine grand sort operation development.
Couple bonus remarks:
a) Calling SQL from PL/SQL objects created with definer rights works like switching to the object owner schema.
b) Using synonyms does not switch temporary tablespace to the tablespace of the referencing objects.
How to rename ASM diskgroup in 11.2
I hope you always do thing right from the first attempt. Sadly I am not. I have generate the Database on incorrectly named ASM Diskgroups.
And there was no space to create the new one to switch to image copy. Luckly it was 11g database that have ASM disk group rename option.
This is the my step by step instruction how to rename ASM diskgroup with RAC database running on it.
INSTRUCTIONS
1.Switch to clusterware environment
2.Get DB configuration
$ srvctl config database -d orcl Database unique name: orcl Database name: Oracle home: /u01/oracle/product/11.2.0/db_1 Oracle user: oracle Spfile: +ORA_FRA/orcl/spfileorcl.ora Domain: Start options: open Stop options: immediate Database role: PRIMARY Management policy: AUTOMATIC Server pools: orcl Database instances: orcl1,orcl2 Disk Groups: ORA_DATA,ORA_REDO,ORA_FRA Mount point paths: Services: srvc_orcl Type: RAC Database is administrator managed
3. Get ASM configuration
$ srvctl config asm -a ASM home: /u01/grid/11.2.0.3 ASM listener: LISTENER ASM is enabled.
4. If there is no SPFILE check init.ora files
$ cat /u01/grid/11.2.0.3/dbs/init+ASM2.ora *.SPFILE='/dev/asmspfile' $ cat /u01/grid/11.2.0.3/dbs/init+ASM1.ora *.SPFILE='/dev/asmspfile'
5. Prepare Database configuration
5.1 Backup spfile
change environment to the orcl
sqlplus "/as sysdba"
create pfile='/u01/oracle/product/11.2.0/db_1/dbs/initorcl.ora.bkp' from spfile; File created.
5.2 Prepare commands to rename files
SQL > select 'ALTER DATABASE RENAME FILE '''||MEMBER||''' TO '''||REPLACE(MEMBER,'+ORA_REDO','+NEW_REDO')||'''; ' FROM v$logfile; SQL > select 'ALTER DATABASE RENAME FILE '''||NAME||''' TO '''||REPLACE(NAME,'+ORA_DATA','+NEW_DATA')||'''; ' FROM v$datafile; SQL > select 'ALTER DATABASE RENAME FILE '''||NAME||''' TO '''||REPLACE(NAME,'+ORA_DATA','+NEW_DATA')||'''; ' FROM v$tempfile;
— sample output
ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_1.271.783943471' TO '+NEW_REDO/orcl/onlinelog/group_1.271.783943471'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_2.259.783944261' TO '+NEW_REDO/orcl/onlinelog/group_2.259.783944261'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_3.269.783943509' TO '+NEW_REDO/orcl/onlinelog/group_3.269.783943509'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_4.267.783943593' TO '+NEW_REDO/orcl/onlinelog/group_4.267.783943593'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_12.265.783944075' TO '+NEW_REDO/orcl/onlinelog/group_12.265.783944075'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_11.257.783944289' TO '+NEW_REDO/orcl/onlinelog/group_11.257.783944289'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_13.263.783944091' TO '+NEW_REDO/orcl/onlinelog/group_13.263.783944091'; ALTER DATABASE RENAME FILE '+ORA_REDO/orcl/onlinelog/group_14.260.783944103' TO '+NEW_REDO/orcl/onlinelog/group_14.260.783944103'; ALTER DATABASE RENAME FILE '+ORA_DATA/orcl/datafile/system.258.783943013' TO '+NEW_DATA/orcl/datafile/system.258.783943013'; ALTER DATABASE RENAME FILE '+ORA_DATA/orcl/datafile/sysaux.262.783942959' TO '+NEW_DATA/orcl/datafile/sysaux.262.783942959'; ALTER DATABASE RENAME FILE '+ORA_DATA/orcl/datafile/undotbs1.261.783942985' TO '+NEW_DATA/orcl/datafile/undotbs1.261.783942985'; ALTER DATABASE RENAME FILE '+ORA_DATA/orcl/datafile/data.263.783942913' TO '+NEW_DATA/orcl/datafile/data.263.783942913'; ALTER DATABASE RENAME FILE '+ORA_DATA/orcl/datafile/undotbs2.259.783943011' TO '+NEW_DATA/orcl/datafile/undotbs2.259.783943011'; ALTER DATABASE RENAME FILE '+ORA_DATA/orcl/tempfile/temp.281.783943239' TO '+NEW_DATA/orcl/tempfile/temp.281.783943239';
5.3 Prepare new initialisation parameter file
$ cp /u01/oracle/product/11.2.0/db_1/dbs/initorcl.ora.bkp /u01/oracle/product/11.2.0/db_1/dbs/initorcl.ora.old $ vi /u01/oracle/product/11.2.0/db_1/dbs/initorcl.ora.bkp
replace
.control_files
.db_create_file_dest
.db_create_online_log_dest_1
.db_create_online_log_dest_2
.db_recovery_file_dest
and all other parameters containing old DISK GROUPS names
5.4 Prepare database for moving: disable block change tracking and flashback
SQL > alter database disable block change tracking; SQL > alter database flashback off;
6. Stop databases
$ Switch to clusterware environment
srvctl stop database -d orcl
7. Unmount Diskgroups on all nodes
$ asmcmd umount ORA_DATA $ asmcmd umount ORA_FRA $ asmcmd umount ORA_REDO
— check that all groups are unmounted
$ asmcmd lsdg
8. Run rename discgroups commands
— stop the second node to leave first node exclusive owner
$ crsctl stop has on node 2 $ renamedg phase=both dgname=ORA_DATA newdgname=NEW_DATA verbose=true $ renamedg phase=both dgname=ORA_FRA newdgname=NEW_FRA verbose=true $ renamedg phase=both dgname=ORA_REDO newdgname=NEW_REDO verbose=true
9. Mount renamed Diskgroups
$ asmcmd mount NEW_DATA $ asmcmd mount NEW_FRA $ asmcmd mount NEW_REDO
— check that all groups are mounted
$ asmcmd lsdg
9. Bring up orcl
change environment to the orcl
$ sqlplus "/as sysdba"
SQL > startup nomount pfile='/u01/oracle/product/11.2.0/db_1/dbs/initorcl.ora.bkp' SQL > alter database mount;
10. Run prepared rename files commands
SQL > ... SQL > create spfile='+NEW_FRA/orcl/spfileorcl.ora' from pfile='/u01/oracle/product/11.2.0/db_1/dbs/initorcl.ora.bkp'
11. modify link to spfile
$ vi /u01/oracle/product/11.2.0/db_1/dbs/initorcl1.ora on node 1
and
$ vi /u01/oracle/product/11.2.0/db_1/dbs/initorcl2.ora on node 2
to poing to new DISKGROUP
12. modify database configuration in clusterware
$ srvctl modify database -d orcl -p +NEW_FRA/orcl/spfileorcl.ora $ srvctl modify database -d orcl -a "NEW_DATA,NEW_FRA,NEW_REDO" $ srvctl config database -d orcl $ srvctl start database -d orcl
13. enable temporary disable functionality
SQL > alter database enable block change tracking; SQL > alter database flashback on;
14. Delete old DISKGROUP RESOURCES
$ crsctl delete resource ora.ORA_DATA.dg $ crsctl delete resource ora.ORA_FRA.dg $ crsctl delete resource ora.ORA_REDO.dg
As result all the configuration that has been done inside database has been saved
MULTISET experiments
Recently I was asked to make some investigation about the PL/SQL procedure running slowly. PL/SQL procedure does not contain any SQL or complicate math operation but for some reasons have unexpected delays in processing. After small investigation I localize the problematic statement as containing the join of two nested tables – “multiset union”.
I was not able to explain it and crate test case to get to the bottom of this issue.
CREATE OR REPLACE PACKAGE epani.multicast_pkg
IS
TYPE t_number_nt IS TABLE OF NUMBER; -- test nested table type
v_new_number t_number_nt; --second nested table
v_number t_number_nt; --first nested table
PROCEDURE init (num_init1 number
, num_init2 number); -- procedure that populate first nested table
PROCEDURE add_number_old; -- procedure that join nested table in old fashion
PROCEDURE add_number_new; -- procedure that join nested tables with MULTISET
END;
/
CREATE OR REPLACE PACKAGE BODY epani.multicast_pkg
IS
PROCEDURE init (num_init1 number -- number of elements in the first table
, num_init2 number) -- number of elements in the second table
is
begin
SELECT num BULK COLLECT INTO v_number FROM (
SELECT LEVEL num FROM DUAL CONNECT BY LEVEL <= num_init1);
SELECT num BULK COLLECT INTO v_new_number FROM (
SELECT LEVEL num FROM DUAL CONNECT BY LEVEL <= num_init2);
end;
PROCEDURE add_number_old
IS
BEGIN
v_number.EXTEND(v_new_number.COUNT); -- allocate nested table
FOR i IN v_new_number.FIRST .. v_new_number.LAST
LOOP
v_number(v_number.LAST) := v_new_number(i);
END LOOP;
END add_number_old;
PROCEDURE add_number_new
IS
BEGIN
v_number:=v_number multiset union v_new_number;
END add_number_new;
END;
/
I have prepared few test cases
First : We join the small table to the big one
---We initialise the first nested table by significant number of rows and second by small number SQL> exec EPANI.multicast_pkg.init(356000,5); PL/SQL procedure successfully completed. Elapsed: 00:00:02.33 -- Run the old fashion join procedure SQL> exec EPANI.multicast_pkg.add_number_old; PL/SQL procedure successfully completed. Elapsed: 00:00:00.01 -- the procedure does not really takes so long SQL> exec EPANI.multicast_pkg.add_number_new; PL/SQL procedure successfully completed. Elapsed: 00:00:00.41 -- the procedure takes almost ½ of time to initially generate the table
Second: we join two relatively small tables but do it repeatedly 1000 times to get the meaningful timing
---We initialise the nested tables by small number of rows
SQL> exec EPANI.multicast_pkg.init(1000,100);
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.05
-- We run pl/sql block using old fashion method
SQL> begin
for i in 1..1000 LOOP
EPANI.multicast_pkg.add_number_old;
END LOOP;
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.15
-- We run pl/sql block using new method
SQL> begin
for i in 1..1000 LOOP
EPANI.multicast_pkg.add_number_new;
END LOOP;
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:04:29.75
Third: We join two big tables
---We initialise the nested tables by significant number of rows SQL> exec EPANI.multicast_pkg.init(100000, 100000); PL/SQL procedure successfully completed. Elapsed: 00:00:02.97 -- Run the old fashion join procedure SQL> exec EPANI.multicast_pkg.add_number_old; PL/SQL procedure successfully completed. Elapsed: 00:00:00.15 -- the procedure does not takes measurable time ---We reinitialise the nested tables by significant number of rows SQL> exec EPANI.multicast_pkg.init(100000, 100000); PL/SQL procedure successfully completed. Elapsed: 00:00:03.11 SQL> exec EPANI.multicast_pkg.add_number_new; PL/SQL procedure successfully completed. Elapsed: 00:00:00.28 -- the procedure takes almost extra 50% above the old method
Forth: We join big tables to the small one
---We initialise the nested tables by significant number of rows SQL> exec EPANI.multicast_pkg.init(5, 356000); PL/SQL procedure successfully completed. Elapsed: 00:00:02.08 -- Run the old fashion join procedure SQL> exec EPANI.multicast_pkg.add_number_old; PL/SQL procedure successfully completed. Elapsed: 00:00:00.62 -- the procedure does takes measurable time ---We reinitialise the nested tables in the same fashion SQL> exec EPANI.multicast_pkg.init(5, 356000); PL/SQL procedure successfully completed. Elapsed: 00:00:02.27 SQL> exec EPANI.multicast_pkg.add_number_new; PL/SQL procedure successfully completed. Elapsed: 00:00:01.07 -- the procedure takes almost extra 50% above the old method
We have proved that for all cases we got better performance on old fashion method in all cases, but why. What stands behind this degradation? The answer can be found if we rewrite our procedures in slightly different way.
CREATE OR REPLACE PACKAGE BODY epani.multicast_pkg
IS
PROCEDURE init (num_init1 number -- number of elements in the first table
, num_init2 number) -- number of elements in the second table
is
begin
SELECT num BULK COLLECT INTO v_number FROM (
SELECT LEVEL num FROM DUAL CONNECT BY LEVEL <= num_init1);
SELECT num BULK COLLECT INTO v_new_number FROM (
SELECT LEVEL num FROM DUAL CONNECT BY LEVEL <= num_init2);
end;
PROCEDURE add_number_old
IS
v_result t_number_nt:= t_number_nt(); --resulting nested table
BEGIN
v_result.EXTEND(v_number.COUNT); -- allocate nested table
FOR i IN v_number.FIRST .. v_number.LAST
LOOP
v_result(v_number.LAST) := v_number(i);
END LOOP;
v_result.EXTEND(v_new_number.COUNT); -- allocate nested table
FOR i IN v_new_number.FIRST .. v_new_number.LAST
LOOP
v_result(v_number.LAST) := v_new_number(i);
END LOOP;
END add_number_old;
PROCEDURE add_number_new
IS
v_result t_number_nt:= t_number_nt(); --resulting nested table
BEGIN
v_result:=v_number multiset union v_new_number;
END add_number_new;
END;
/
And repeat our tests
First : We join the small table to the big one
---We initialise the first nested table by significant number of rows and second by small number SQL> exec EPANI.multicast_pkg.init(356000,5); PL/SQL procedure successfully completed. Elapsed: 00:00:02.16 -- Run the old fashion join procedure SQL> exec EPANI.multicast_pkg.add_number_old; PL/SQL procedure successfully completed. Elapsed: 00:00:00.93 -- the procedure does takes significantly longer SQL> exec EPANI.multicast_pkg.add_number_new; PL/SQL procedure successfully completed. Elapsed: 00:00:00.64 -- faster by new method
Second: we join two relatively small tables but do it repeatedly 1000 times to get the meaningful timing
---We initialise the nested tables by small number of rows
SQL> exec EPANI.multicast_pkg.init(1000,100);
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.04
-- We run pl/sql block using old fashion method
SQL> begin
for i in 1..1000 LOOP
EPANI.multicast_pkg.add_number_old;
END LOOP;
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:02.30
-- We run pl/sql block using new method
SQL> begin
for i in 1..1000 LOOP
EPANI.multicast_pkg.add_number_new;
END LOOP;
end;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.96
-- Faster by new method
Third: We join two big tables
---We initialise the nested tables by significant number of rows SQL> exec EPANI.multicast_pkg.init(100000, 100000); PL/SQL procedure successfully completed. Elapsed: 00:00:01.56 -- Run the old fashion join procedure SQL> exec EPANI.multicast_pkg.add_number_old; PL/SQL procedure successfully completed. Elapsed: 00:00:00.48 -- the procedure does not takes measurable time ---We reinitialise the nested tables by significant number of rows SQL> exec EPANI.multicast_pkg.init(100000, 100000); PL/SQL procedure successfully completed. Elapsed: 00:00:02.08 SQL> exec EPANI.multicast_pkg.add_number_new; PL/SQL procedure successfully completed. Elapsed: 00:00:00.40 -- slightly faster by new method
Forth: We join big tables to the small one
---We initialise the nested tables by significant number of rows SQL> exec EPANI.multicast_pkg.init(5, 356000); PL/SQL procedure successfully completed. Elapsed: 00:00:01.31 -- Run the old fashion join procedure SQL> exec EPANI.multicast_pkg.add_number_old; PL/SQL procedure successfully completed. Elapsed: 00:00:00.58 -- the procedure does takes measurable time ---We reinitialise the nested tables in the same fashion SQL> exec EPANI.multicast_pkg.init(5, 356000); PL/SQL procedure successfully completed. Elapsed: 00:00:01.38 SQL> exec EPANI.multicast_pkg.add_number_new; PL/SQL procedure successfully completed. Elapsed: 00:00:00.50 -- slightly faster by new method
It looks like that for new set of test MULTICAST shows better performance than the handmade one. The answer is lighting in a scope of functionality. When we add one collection to the already existing the old one works perfectly but when we create the new collection as join of two old one and later assign it to the one of them the MULTICAST shows better efficiency. Multicast is able to resolve the vide scope of tasks. The developers should clearly see the difference between operating two collections or three collections and choose the appropriate method based on application requirements.
Partition pruning using non-prefixed local indexes
This small post is from nice and frighten world of partitions, specifically the case of partition pruning. If you are using partitions in your application there is fair chance that your database is quite big and performance demanding. If you are not working in classic Data Warehousing manner you have to care about DML statement performance. One of the basic rules of DML performance is less indexes you have and less index columns in existing indexes then higher is the DML performance. Thus one of the architectural DBA targets is to reduce the number of indexed columns by just most critical. Another axiom statement is that smaller indexes is easier to support and manage then big one, thus local indexes usually more preferable. The conclusion from two previous axiom is that probably most indexes on partitioned tables in your application is non-prefixed local indexes. Now we came to the topic of this post how oracle optimizer deal with such indexes and what we can do with it.
Lets create list base partitioned table transactions
| Column Name | Comment |
| SERNO | Unique identifier |
| PARTITIONKEY | Partition Key |
| SGENERAL | Some indexed Field |
And create two indexes TRANSACTIONS_PK (SERNO, PARTITIONKEY) and local partitioned non-prefixed index TRANSACTIONSI (SGENERAL).
Let’s start from the most common statement
EXPLAIN PLAN FOR SELECT SGENERAL, count(1) FROM transactions WHERE PARTITIONKEY='JUL2012' AND SGENERAL is not null GROUP BY SGENERAL;
PLAN_TABLE_OUTPUT
———————————————————————————————————————————————-
Plan hash value: 2338610280
| Id | Operation | Name |
Rows |
Bytes |
Cost |
Time |
Pstart |
Pstop |
| 0 | SELECT STATEMENT |
5 |
55 |
69978 (1) |
00:14:00 |
|||
| 1 | HASH GROUP BY |
5 |
55 |
69978 (1) |
00:14:00 |
|||
| 2 | PARTITION LIST SINGLE |
5340K |
56M |
69727 (1) |
00:13:57 |
KEY |
KEY |
|
| *3 | TABLE ACCESS FULL | TRANSACTIONS |
5340K |
56M |
69727 (1) |
00:13:57 |
19 |
19 |
Predicate Information (identified by operation id):
—————————————————
3 – filter(“STGENERAL” IS NOT NULL)
Does it look like non-optimal? Optimizer has chosen to do FULL SCAN even if it has nice looking index TRANSACTIONSI. The problem is that partition pruning works only for prefixed indexes, that means you have to pay for support extra column in your index even if you do not need it because you clearly can get the partition name based from the identical rules on a table.
But luckily we have extended syntaxes. Uses it we can manually define the partition that should be used. In our case the partition name is equal to the partition key. Getting the partition name is very simple for list partitions but can be received in all other cases too.
EXPLAIN PLAN FOR
SELECT SGENERAL, count(1)
FROM TRANSACTIONS PARTITION ("JUL2012")
WHERE SGENERAL is not null
GROUP BY SGENERAL;
PLAN_TABLE_OUTPUT
———————————————————————————————————————————————-
Plan hash value: 198159339
| Id | Operation | Name |
Rows |
Bytes |
Cost |
Time |
Pstart |
Pstop |
| 0 | SELECT STATEMENT |
4 |
20 |
10 (20) |
00:00:01 |
|||
| 1 | SORT GROUP BY NOSORT |
4 |
20 |
10 (20) |
00:00:01 |
|||
| 2 | PARTITION LIST SINGLE |
8890 |
44450 |
8 (0) |
00:00:01 |
KEY |
KEY |
|
| *3 | INDEX FULL SCAN | TRANSACTIONSI |
8890 |
44450 |
8 (0) |
00:00:01 |
19 |
19 |
Predicate Information (identified by operation id):
—————————————————
3 – filter(“SGENERAL” IS NOT NULL)
This plan looks much better. According to optimizer estimations we can save 14 minutes on it. But there is even more attractive syntaxes for those who do not want to spend their time calculating the partition name
EXPLAIN PLAN FOR
SELECT SGENERAL, count(1)
FROM TRANSACTIONS PARTITION FOR ('JUL2012')
WHERE SGENERAL is not null
GROUP BY SGENERAL;
PLAN_TABLE_OUTPUT
———————————————————————————————————————————————
Plan hash value: 198159339
| Id | Operation | Name |
Rows |
Bytes |
Cost |
Time |
Pstart |
Pstop |
| 0 | SELECT STATEMENT |
4 |
20 |
10 (20) |
00:00:01 |
|||
| 1 | SORT GROUP BY NOSORT |
4 |
20 |
10 (20) |
00:00:01 |
|||
| 2 | PARTITION LIST SINGLE |
8890 |
44450 |
8 (0) |
00:00:01 |
KEY |
KEY |
|
| *3 | INDEX FULL SCAN | TRANSACTIONSI |
8890 |
44450 |
8 (0) |
00:00:01 |
19 |
19 |
Predicate Information (identified by operation id):
—————————————————
3 – filter(“SGENERAL” IS NOT NULL)
The only problem with last syntax is that it is supported only from 11.2 version. The syntax was developed to support interval partitions but can be handy for all other types.
Does it looks that with new syntax we came to the kingdom of wealth and prosperity, where we can easily avoid prefixes on local indexes and still use the effective partition pruning? But it is not. The hidden rock is that the partition keys in PARTITION FOR clause could not be defined throw the variables like in WHERE clause. Below there are examples of such attempt
Firstly traditional approach
DECLARE v_part char(7):='JUL2012'; BEGIN FOR REC IN (SELECT SGENERAL, count(1) FROM TRANSACTIONS WHERE PARTITIONKEY=v_part AND SGENERAL is not null GROUP BY SGENERAL) LOOP NULL; END LOOP; END; / Elapsed: 00:12:42.05
It works but does not looks like very performance effective. Let’s go and try 10g approach in PL/SQL
DECLARE v_part varchar2(10):="JUL2012"; BEGIN FOR REC IN (SELECT SGENERAL, count(1) FROM TRANSACTIONS PARTITION (v_part) WHERE SGENERAL is not null GROUP BY SGENERAL) LOOP NULL; END LOOP; END; / ERROR at line 2: ORA-06550: line 2, column 25: PLS-00201: identifier "JUL2012" must be declared ORA-06550: line 2, column 10: PL/SQL: Item ignored
It looks like kind of expected behavior. You could not use table name as variable, why you should be able to use partition name. Personally I put a lot of hope on the last test with PARTITIONKEY reference
DECLARE<span style="color: #000000;"> v_part char(7):='JUL2012'; BEGIN FOR REC IN (SELECT SGENERAL, count(1) FROM TRANSACTIONS PARTITION FOR (v_part) WHERE SGENERAL is not null GROUP BY SGENERAL) LOOP NULL; END LOOP; END; / ERROR at line 1: ORA-14763: Unable to resolve FOR VALUES clause to a partition number ORA-06512: at line 4
It was the first time I see the error thus have a look into the documentation
ORA-14763: Unable to resolve FOR VALUES clause to a partition number
Cause: Could not determine the partition corresponding to the FOR VALUES clause.
Action: Remove bind variables and dependencies on session parameters from the values specified in the FOR VALUES clause.
Ha-Ha-Ha nothing change we still could not pass partition key values into query.
Summarizing oracle offer the mechanism that allows to use partition pruning on non-prefixed local indexes but have not support the syntaxes in pl/sql using binds. The usage of this syntaxes have sense only in case of big queries (e.g. reports) running on a table, when gains from effective execution plan prevail over the loses of dynamic sql.
Application Code Level script
With patches and fixes delivered to different sites and applying to different testing, verification and production regions, there is a need for a simple way to compare database objects in the application schema without having database link between different databases. This can be challenging as the PL/SQL code is usually encrypted and database segments have different storage attributes. Here I show the method to achieve this comparison.
The reason why I think it would be interesting to public is that the problem is very common and up to day. There is no common white paper that helps to solve it. The only note that pretends to cover the topic is 781719.1 But it speaks only about PL/SQL objects that are not enough in a real world.
The attached script use MD5 hashing algorithm to get hash value associated to the version of database object. The hashing CLOB can be get from DBMS_METADATA package or from DBA_SOURCE view for PL/SQL objects. The principals are very simple but there are few points that have been raised during development.
1. The tables, indexes and e.t.c. with different storage configuration should generate the same hash. This issue has been solved by DBMS_METADATA.SET_TRANSFORM_PARAM
2. The tables with different order of columns and constraints have to provide the same hash too. The solution was to use Simple XML format of DBMS_METADATA output and sorting the columns and constraints alphabetically using XML functions.
3. The nested and index organise service tables are included into DBA_OBJECTS as TABLES but DBMS_METADATA include their description into the master objects but failed on servant items. My solution was to use DBA_TABLES view to segregate only high level objects.
4. Java objects has no option to generate description in XML format thus we generate it in general DDL format.
5. Role description should include grants that have been granted to the role. The DBMS_METADA does not include grants into generated description thus again the XML functions was used to get proper CLOB
The following privileges required for the user who run the script
-- GRANT CREATE PROEDURE
-- GRANT EXECUTE ON DBMS_CRYPTO
-- GRANT EXECUTE ON DBMS_METADATE
-- GRANT SELECT ON DBA_SOURCE
-- GRANT SELECT ON DBA_SYS_PRIVS
-- GRANT SELECT ON DBA_TAB_PRIVS
-- GRANT SELECT ON DBA_ROLE_PRIVS
The following script take one parameter – the application schema name and provide as output list of database objects with corresponding hash values.
create or replace function verify_source(p_source_type in varchar2,
p_source_name in varchar2,
p_source_owner in varchar2) return varchar2 AUTHID CURRENT_USER as
code_source clob;
md5hash varchar2(32);
v_h NUMBER; -- handle returned by OPEN
v_th NUMBER; -- handle returned by ADD_TRANSFORM
begin
IF p_source_type in ('VIEW','ROLE','TABLE','INDEX'
,'MATERIALIZED_VIEW','MATERIALIZED_VIEW_LOG','SEQUENCE','SYNONYM') THEN
v_h := DBMS_METADATA.OPEN(p_source_type);
if p_source_type not in ('ROLE') THEN
DBMS_METADATA.SET_FILTER(v_h,'SCHEMA',p_source_owner);
END IF;
DBMS_METADATA.SET_FILTER(v_h,'NAME',p_source_name);
v_th := DBMS_METADATA.ADD_TRANSFORM(v_h,'SXML');
if p_source_type not in ('VIEW','ROLE') THEN
DBMS_METADATA.SET_TRANSFORM_PARAM (v_th,'SEGMENT_ATTRIBUTES',FALSE);
DBMS_METADATA.SET_TRANSFORM_PARAM (v_th,'STORAGE',FALSE);
DBMS_METADATA.SET_TRANSFORM_PARAM (v_th,'TABLESPACE',FALSE);
DBMS_METADATA.SET_TRANSFORM_PARAM (v_th,'PARTITIONING',FALSE);
END IF;
code_source := DBMS_METADATA.FETCH_CLOB(v_h);
IF p_source_type in ('TABLE') THEN
-- get rid off sorting misconfigurations
SELECT UPDATEXML(
UPDATEXML(SRC,'/TABLE/RELATIONAL_TABLE/COL_LIST',
XMLELEMENT("COL_LIST", (
XMLQuery (
'for $i in /TABLE/RELATIONAL_TABLE/COL_LIST/COL_LIST_ITEM
order by $i/NAME
return $i'
passing by value SRC
RETURNING CONTENT
)
) )
) ,'/TABLE/RELATIONAL_TABLE/FOREIGN_KEY_CONSTRAINT_LIST',
XMLELEMENT("FOREIGN_KEY_CONSTRAINT_LIST", (
XMLQuery (
'for $i in
/TABLE/RELATIONAL_TABLE/FOREIGN_KEY_CONSTRAINT_LIST/FOREIGN_KEY_CONSTRAINT_LIST_ITEM
order by $i/NAME
return $i'
passing by value SRC
RETURNING CONTENT
)
) )
).getClobVal() INTO code_source
FROM ( SELECT XMLQuery(
'declare function local:removeNS($e as element()) as element()
{
element { QName("", local-name($e)) }
{
for $i in $e/node()|$e/attribute::*
return typeswitch ($i)
case element() return local:removeNS($i)
default return $i
}
}; (::)
local:removeNS($SRC/child::*)'
passing XMLType(code_source) as "SRC"
returning content
) SRC
FROM dual) INITSRC;
END IF;
DBMS_METADATA.CLOSE(v_h);
ELSIF p_source_type in ('PROCEDURE','FUNCTION','TYPE','TYPE BODY','TRIGGER','PACKAGE','PACKAGE BODY')
THEN
code_source := '';
for source_record in (select text from dba_source where owner = upper(p_source_owner) and name =
upper(p_source_name) and type = upper(p_source_type) order by line)
loop
code_source := code_source||source_record.text;
end loop;
ELSIF p_source_type in ('JAVA_CLASS','JAVA_SOURCE') THEN
code_source := DBMS_METADATA.GET_DDL(p_source_type,p_source_name,upper(p_source_owner));
ELSIF p_source_type in ('ROLE') THEN
SELECT
INSERTCHILDXMLAFTER(SRC,'/ROLE','TYPE[1]',
(SELECT
XMLAgg(
XMLELEMENT("privs",
XMLFOREST(OWNER, TABLE_NAME, PRIVILEGE)))
FROM
(SELECT DISTINCT *
FROM (
SELECT OWNER, TABLE_NAME, PRIVILEGE
FROM dba_tab_privs
WHERE GRANTEE IN
(SELECT GRANTED_ROLE
FROM DBA_ROLE_PRIVS
START WITH GRANTEE=p_source_name
CONNECT BY NOCYCLE PRIOR GRANTED_ROLE=GRANTEE
UNION ALL
SELECT p_source_name FROM DUAL)
UNION ALL
SELECT NULL OWNER, PRIVILEGE TABLE_NAME, NULL PRIVILEGE
FROM dba_sys_privs
WHERE GRANTEE IN (SELECT GRANTED_ROLE
FROM DBA_ROLE_PRIVS
START WITH GRANTEE=p_source_name
CONNECT BY NOCYCLE PRIOR GRANTED_ROLE=GRANTEE
UNION ALL
SELECT p_source_name FROM DUAL))
ORDER BY 1,2,3))).getClobVal() INTO code_source
FROM ( SELECT XMLQuery(
'declare function local:removeNS($e as element()) as element()
{
element { QName("", local-name($e)) }
{
for $i in $e/node()|$e/attribute::*
return typeswitch ($i)
case element() return local:removeNS($i)
default return $i
}
}; (::)
local:removeNS($SRC/child::*)'
passing XMLType(code_source) as "SRC"
returning content
) SRC
FROM dual) INITSRC;
END IF;
md5hash := rawtohex(dbms_crypto.hash(typ => dbms_crypto.HASH_MD5,
src => code_source));
return md5hash;
exception
WHEN OTHERS THEN
return p_source_type||p_source_name;
end;
/
show error
Spool code_level_checksum.lst
set pagesize 5000
set heading off
set echo off
set feedback off
col OBJECT_TYPE FORMAT a30
col OBJECT_NAME FORMAT a30
col HASHVAL FORMAT a35
prompt ###################################
prompt # TABLES #
prompt ###################################
SELECT 'TABLE' OBJECT_TYPE, TABLE_NAME OBJECT_NAME , verify_source('TABLE',TABLE_NAME, OWNER)
HASHVAL
FROM DBA_TABLES WHERE OWNER='&1'
AND IOT_NAME IS NULL
order by 1,2
/
prompt ###################################
prompt # INDEXES #
prompt ###################################
SELECT 'INDEX' OBJECT_TYPE, INDEX_NAME OBJECT_NAME , verify_source('INDEX',INDEX_NAME, OWNER)
HASHVAL
FROM DBA_INDEXES WHERE OWNER='&1'
order by 1,2
/
prompt ###################################
prompt # ROLES #
prompt ###################################
SELECT 'ROLE' OBJECT_TYPE, ROLE OBJECT_NAME , verify_source('ROLE',ROLE, 'TCTDBS') HASHVAL
FROM DBA_ROLES
order by 1,2
/
prompt ###################################
prompt # JAVA SOURCES #
prompt ###################################
select OBJECT_TYPE, OBJECT_NAME, verify_source('JAVA_SOURCE',OBJECT_NAME, OWNER) HASHVAL FROM
dba_objects
WHERE OWNER='&1' and OBJECT_TYPE IN ('JAVA SOURCE')
order by 1,2
/
prompt ###################################
prompt # JAVA CLASSES #
prompt ###################################
select 'JAVA_CLASS' OBJECT_TYPE, NAME OBJECT_NAME, verify_source('JAVA_CLASS',NAME, OWNER) HASHVAL
FROM dba_java_classes
WHERE OWNER='&1'
order by 1,2
/
prompt ###################################
prompt # MISC #
prompt ###################################
select OBJECT_TYPE, OBJECT_NAME, verify_source(OBJECT_TYPE,OBJECT_NAME, OWNER) HASHVAL FROM
dba_objects
WHERE OWNER='&1' and OBJECT_TYPE IN ('PROCEDURE','FUNCTION','TYPE','TYPE
BODY','TRIGGER','VIEW','MATERIALIZED_VIEW','MATERIALIZED_VIEW_LOG','SEQUENCE','SYNONYM','PACKAGE','PACKAG
E BODY')
order by 1,2
/
spool off;
drop function verify_source
/
Hope you will find it usefull.
The output from this script can be compared as simple flat file using any favorite comparison tool, e.g. WinMerge.
TO_CHAR or NOT TO_CHAR
Another post where I probably show trivial things. This issue is very easy to diagnose and fix but quite complicate to prevent.
I’ll start from my personal statistics of performance analyses during development. From my point of view there are 5 levels of SQL tuning that are using in code development. I try to present percent of queries that tuned by each of them.
| N | Method | % of statement tested |
| 1 | No test. Rely on optimizer and experience. | 50 |
| 2 | Execute on developer database. | 25 |
| 3 | Execute on a database with real size data. | 15 |
| 4 | Execute on database with real size data and analyse the execution plan. | 10 |
| 5 | Execute on database with real size data and analyse the execution plan and predicates. | 0.0000001 |
It shows that usually we usually start intensively tune queries only when it does not work on a real production or preproduction stage. It have sense but some hidden rocks can and should be diagnosed during using the first level of tuning. Based on my own experience the own expertise can be easily overestimated. Before I start this post I query some my friends and no one was aware this oracle trick, thus I believe that it would be useful for general audience too.
Will you check the predicates if the access method is expected and use the correct index. Probably not but oracle loves to make surprises. In our case it was surprise with concatenated indexes and implicit conversion.
I’ll try to show the case using the example
--Create sample table
CREATE TABLE eterpani.TESTTABLE
( COL1 NUMBER(10,0) DEFAULT (0) NOT NULL ENABLE,
ID NUMBER(10,0) NOT NULL ENABLE,
PARTITIONKEY CHAR(1) NOT NULL ENABLE,
COL2 NUMBER(10,0),
COL3 VARCHAR2(6 CHAR) NOT NULL ENABLE,
COL4 DATE NOT NULL ENABLE,
COL5 VARCHAR2(3 CHAR) NOT NULL ENABLE,
AMOUNT NUMBER(16,3) DEFAULT (0) NOT NULL ENABLE,
CONSTRAINT TESTTABLE_PK PRIMARY KEY (ID,PARTITIONKEY) USING INDEX )
/
--Put concatenated index on it where col2 column is in the middle
CREATE INDEX eterpani.TESTTABLE_IDX1 ON eterpani.TESTTABLE
(PARTITIONKEY, COL4, COL5, COL2, COL3)
/
--Populate table by some data
INSERT INTO eterpani.TESTTABLE
SELECT COL1, ID, PARTITIONKEY, COL2, COL3, COL4,COL5,AMOUNT FROM dual
MODEL DIMENSION by (65 i)
MEASURES (0 COL1,
0 ID,
CAST(' ' as CHAR(1)) PARTITIONKEY,
0 COL2,
CAST(' ' as CHAR(25)) COL3,
sysdate COL4,
CAST(' ' as CHAR(3)) COL5,
0 AMOUNT)
(col1[for i from 1 to 100000 increment 1] = ROUND(DBMS_RANDOM.VALUE(100,150)),
ID[for i from 1 to 100000 increment 1] = cv(i),
PARTITIONKEY[for i from 1 to 100000 increment 1] = CHR(65+MOD(cv(i),26)),
col2[for i from 1 to 100000 increment 1] = ROUND(DBMS_RANDOM.VALUE(10,12)),
col3[for i from 1 to 100000 increment 1] = PARTITIONKEY[cv(i)]||DBMS_RANDOM.STRING('U',5),
col4[for i from 1 to 100000 increment 1] = TRUNC(SYSDATE)+ROUND(DBMS_RANDOM.VALUE(-5,5)),
col5[for i from 1 to 100000 increment 1] = TO_CHAR(ROUND(DBMS_RANDOM.VALUE(10,999))),
AMOUNT[for i from 1 to 100000 increment 1] = ROUND(DBMS_RANDOM.VALUE(100,1000)))
/
COMMIT
/
The preparation steps are over. Lets run the query.
Set autotrace on
SELECT PARTITIONKEY, COL4, COL3, COL2, COL5, SUM(AMOUNT) SUMAMOUNT
FROM eterpani.TESTTABLE
WHERE PARTITIONKEY = 'C' AND COL3='COWRTE'
AND COL4 = TRUNC(SYSDATE) AND COL2 = 11
AND COL5 = 901 AND COL1=131
GROUP BY PARTITIONKEY, COL4, COL5, COL2, COL3;
Let’s look on execution plan
Execution Plan ---------------------------------------------------------- Plan hash value: 3717891987 ------------------------------------------------------------------------------------------- |Id| Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------- | 0|SELECT STATEMENT | | 1 | 59 | 4 (0) | 00:00:01 | | 1| SORT GROUP BY NOSORT | | 1 | 59 | 4 (0) | 00:00:01 | |*2| TABLE ACCESS BY INDEX ROWID| TESTTABLE | 1 | 59 | 4 (0) | 00:00:01 | |*3| INDEX RANGE SCAN | TESTTABLE_IDX1 | 1 | | 4 (0) | 00:00:01 |
If someone had showed me this execution plan few months ago I would have said that it is the good one without any doubts. But let me make a small changes in a query – put explicit conversion to COL5 predicate.
Set autotrace on
SELECT PARTITIONKEY, MAX(COL1), COL4, COL3, COL2, COL5, SUM(AMOUNT) SUMAMOUNT
FROM eterpani.TESTTABLE
WHERE PARTITIONKEY = 'C' AND COL3='COWRTE'
AND COL4 = TRUNC(SYSDATE) AND COL2 = 11
AND COL5 = TO_CHAR(901) AND COL1=131
GROUP BY PARTITIONKEY, COL4, COL5, COL2, COL3;
As result we have the same execution plan. Even the “Plan hash value” is the same. At this stage you can say no difference no reasons to bother. But difference exists. Firstly pay attention to the bottom part of the autotrace output
| Without TO_CHAR | Statistics ———————————————————- 0 recursive calls 0 db block gets 9 consistent gets 0 physical reads 0 redo size 675 bytes sent via SQL*Net to client 513 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed |
| With TO_CHAR | Statistics ———————————————————- 0 recursive calls 0 db block gets 3 consistent gets 0 physical reads 0 redo size 746 bytes sent via SQL*Net to client 513 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed |
Does the triple number of read blocks confuse you? The answer on this confusion is in the middle part of autotrace output
| Without TO_CHAR | Predicate Information (identified by operation id): ————————————————— 2 – filter(“COL1″=131) |
| With TO_CHAR | Predicate Information (identified by operation id): ————————————————— 2 – filter(“COL1″=131) |
As you understand the most selective predicate in this query is “COL3=’COW131’”. This predicate use indexed column and mentioned in corresponding section thus everything should be easy and strait forward. But there is one small difference. Oracle implicitly convert all values in COL5 to number. Why Oracle is doing it gods know. But it prevent usage of COL5 in access path. Even without explicit conversion we still use the index but read more blocks.
I have tried to describe this difference in reading on a picture
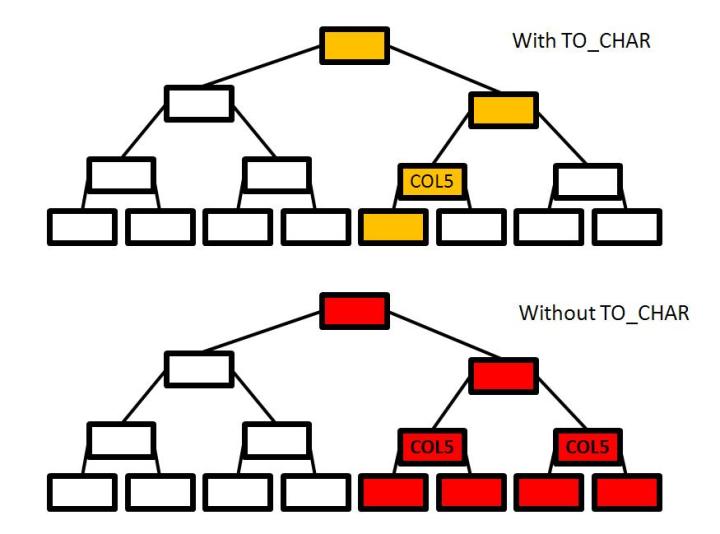
All index blocks with the same PARTITIONKEY and COL4 values would be reviewed in a process of searching the relevant records. It is just index blocks reading but it is additional read operation that can dramatically increase the time query depending on cardinality of COL5. Moreover we have extra CPU waste. Instead of one conversion operation from constant to char we convert each single COL5 value to number. Believe me it is not we all expected on our databases.
There are two conclusions on above information:
firstly – be careful when looking on execution plan, check not only plan but predicates and other bits and pieces
Secondly – implicit thing have tendency to work unpredictably. Convert explicitly where you can.
Usefull doc: ORA-01722: Invalid Number; Implicit Conversion Not Working Correctly [ID 743595.1]
